Volver
El entorno de Power Pivot
 Podemos acceder a Power Pivot desde este botón
Podemos acceder a Power Pivot desde este botón
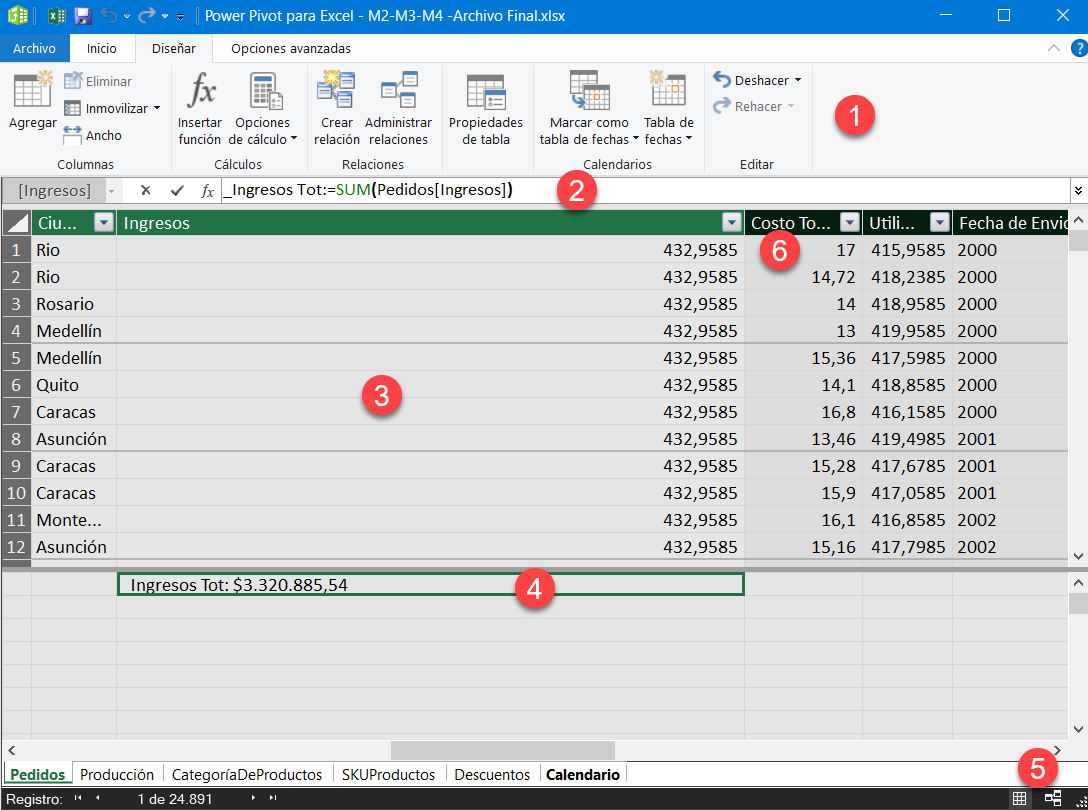
- Menú de opciones
- Barra de fórmulas
- Área de datos
- Área de medidas o campos calculados
- Barra para cambiar entre vista de diagrama y vista de tabla
- Columnas calculadas, se distinguen por su color negro
¿Qué es un modelo de datos?
Una de las funciones principales de los sistemas computacionales es la de manejar y almacenar grandes cantidades de información. Un modelo de datos describe la estructura de esos datos que están almacenados en dichos sistemas.
 El objetivo principal de un modelo de datos es darnos información sobre la manera en que están almacenados los datos. También podríamos definir el modelo de datos como un mapa que nos ayudará a comprender la forma en que se han organizado y almacenado los datos.
El objetivo principal de un modelo de datos es darnos información sobre la manera en que están almacenados los datos. También podríamos definir el modelo de datos como un mapa que nos ayudará a comprender la forma en que se han organizado y almacenado los datos.
Dentro de la teoría de bases de datos encontrarás diferentes tipos de modelos, pero el que nos interesa y que es relevante para nuestro trabajo con Power Pivot, es el modelo de datos relacional.
El modelo de datos relacional
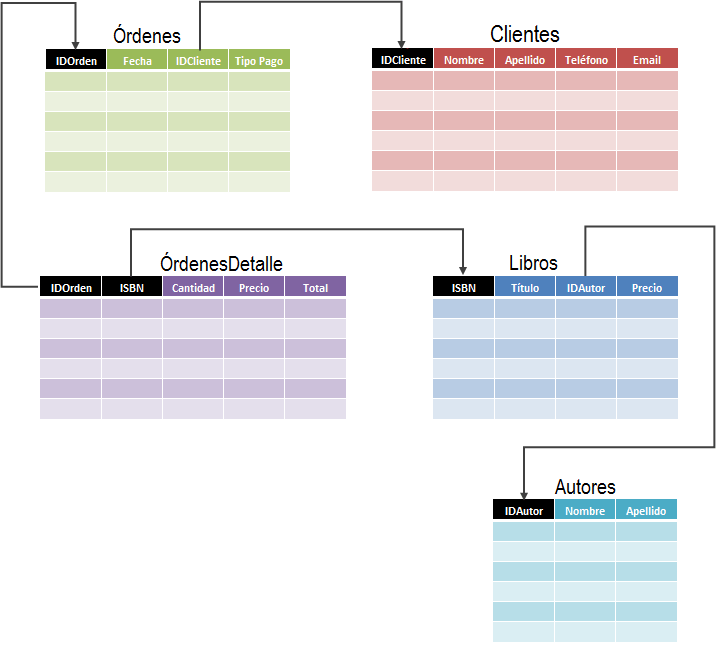
Comprender la teoría de datos relacionales podría llevarnos todo un curso, pero para hacer las cosas extremadamente simples, podría decir que este modelo nos dice que los datos pueden representarse por un conjunto de tablas que estarán vinculadas entre sí por un campo en común.
En la práctica, es común referirnos a estos elementos como tablas y relaciones. Una tabla está formada por columnas y filas mientras que una relación nos indica la columna que ha sido utilizada para vincular a dos tablas entre sí. Pero ¿por qué querría tener muchas tablas cuando toda la información puede estar contenida en una sola? ¿Qué beneficios tiene distribuir la información en múltiples tablas? Esta es una pregunta muy común y totalmente válida para los usuarios que comienzan en el modelado de datos y la razón la explicaré con un ejemplo.
Supondremos el caso de una empresa que se dedica a vender teléfonos móviles y en los últimos días se han realizado varias ventas que han sido registradas de la siguiente manera:
 Quiero que pongas atención en las columnas Cliente, Email y Teléfono las cuales tienen información de contacto del cliente que ha hecho la compra. Ya que la empresa tiene clientes recurrentes, la información se vuelve a repetir cada vez que el mismo cliente hace una compra y eso puede traernos algunos problemas. A continuación menciono algunos de esos problemas:
Quiero que pongas atención en las columnas Cliente, Email y Teléfono las cuales tienen información de contacto del cliente que ha hecho la compra. Ya que la empresa tiene clientes recurrentes, la información se vuelve a repetir cada vez que el mismo cliente hace una compra y eso puede traernos algunos problemas. A continuación menciono algunos de esos problemas:
-
El ingreso de nuevos datos: Si en alguna nueva compra se ingresa de manera incorrecta la información de contacto del cliente, ya no habrá manera de saber cuál de todos los datos es correcto o incorrecto. Por ejemplo, si la próxima compra de Hugo Ramírez se ingresa el correo electrónico hugo2@email.com no habrá certeza sobre cuál de los dos correos es correcto en el historial de compras de Hugo.
-
La actualización de datos: Si Hugo Ramírez cambia de Teléfono de contacto y queremos mantener actualizada la tabla anterior, será necesario modificar cada fila con la nueva información de Hugo. Siempre existe la posibilidad de omitir el cambio en alguna fila y de nueva cuenta no sabremos cuál de los teléfonos es el correcto.
-
El espacio de almacenamiento: Cada letra y palabra ingresada en la tabla se traduce en bytes de información en el disco del equipo. Entra más grande sea la cantidad de datos repetidos, mayor será el tamaño de la base de datos. No hace mucho sentido guardar información repetida que puede tener algún impacto en el rendimiento de una base de datos.
Estos son algunos de los problemas que te puedes encontrar al colocar todos los datos en una sola tabla.
Por supuesto, el impacto será mayor conforme la base de datos crezca, así que es conveniente cuidar estos aspectos de diseño desde el principio.
Para evitar estos problemas en nuestro ejemplo, debemos dividir la tabla original en dos tablas de la siguiente manera:
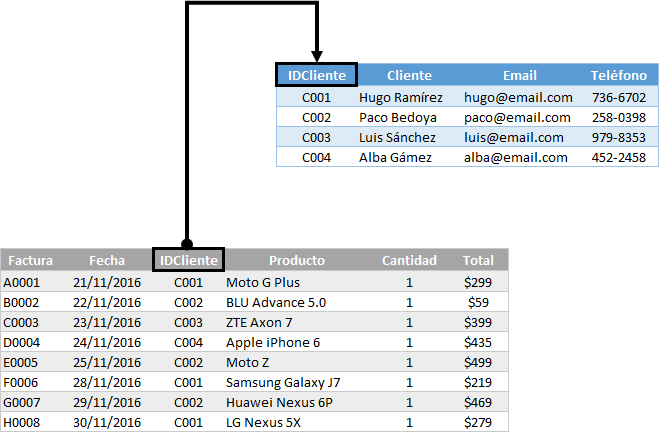 Las tres columnas Cliente, Email y Teléfono, que hacían referencia a la información del cliente, ahora son una tabla independiente y se ha agregado una columna adicional que funciona como un identificador único (Llave) para cada cliente. De esta manera, cuando queremos hacer referencia a un cliente desde otra tabla, podemos utilizar su identificador único.
Las tres columnas Cliente, Email y Teléfono, que hacían referencia a la información del cliente, ahora son una tabla independiente y se ha agregado una columna adicional que funciona como un identificador único (Llave) para cada cliente. De esta manera, cuando queremos hacer referencia a un cliente desde otra tabla, podemos utilizar su identificador único.
La gran ventaja de este cambio es que solo debemos enfocarnos en la tabla que contiene la información de los clientes para hacer cualquier modificación. No será necesario hacer actualizaciones en diferentes filas o tablas, ya que ahora toda la información que se refiere a los clientes está en una sola tabla. De esa manera también reducimos el espacio requerido para el almacenamiento de los datos.
De eso se trata el modelado de datos, de adoptar buenas prácticas que hagan más eficientes nuestras bases de datos. A este proceso de “mejora” se le conoce como Normalización de bases de datos y es la aplicación de un conjunto de reglas (Formas normales) a una base de datos. Cuando una base de datos cumple con las formas normales, se dice que la base de datos ha sido normalizada.